
ballqs 님의 블로그
[Spring] 웨이팅 대기열 트러블 슈팅 본문
부트캠프를 통해 다양한 기술들을 배우고 실습하며, 최종 프로젝트로 실시간 맛집 예약 서비스를 개발하게 되었습니다. 이 서비스는 최근 외식 수요 증가로 긴 대기시간이 대두되었고 음식점 앞에서 직접 기다리는 불편함을 줄이고, 실시간으로 남은 대기 순서를 확인할 수 있게 하여 요율적이고 편리한 외식 경험을 제공하자는 취지로 시작했습니다.
프로젝트의 핵심 기능 중 하나는 웨이팅 대기열 시스템입니다. 사용자가 음식점에 웨이팅을 걸면 발권번호를 받아서 대기 상태에 들어가며 음식점에서 이를 확인하고 입장할 수 있도록 돕는 시스템입니다. 그러나 초기 개발 단계에서 발권번호 중복 및 데이터 불일치 문제가 발생하면서 동시성 제어에 대한 고민이 시작되었습니다.
처음에는 단순하게 DB CRUD 방식으로 구현했으나 높은 트래픽 상황에서 발권번호가 중복되는 등 서비스 안정성에 치명적인 문제가 드러났고 이를 해결하기 위해 Redis를 도입했습니다. Redis 내에서도 여러 구현 방식을 테스트하면서 최적화된 해결책을 찾아야 했습니다.
이번 글에서는 대기열 발권번호 중복 문제와 동시성 제어를 해결하기 위한 과정, 그리고 성능을 중시한 접근 방식과 그 결과를 정리해보겠습니다.
최종적으로는 RAtomicLong + RScoredSortedSet + RedissonLock(리뉴얼) 로 선택해서 마무리 했다는 점을 미리 말씀드립니다.
※ 한눈에 보는 차트
문제 의식
발생한 문제
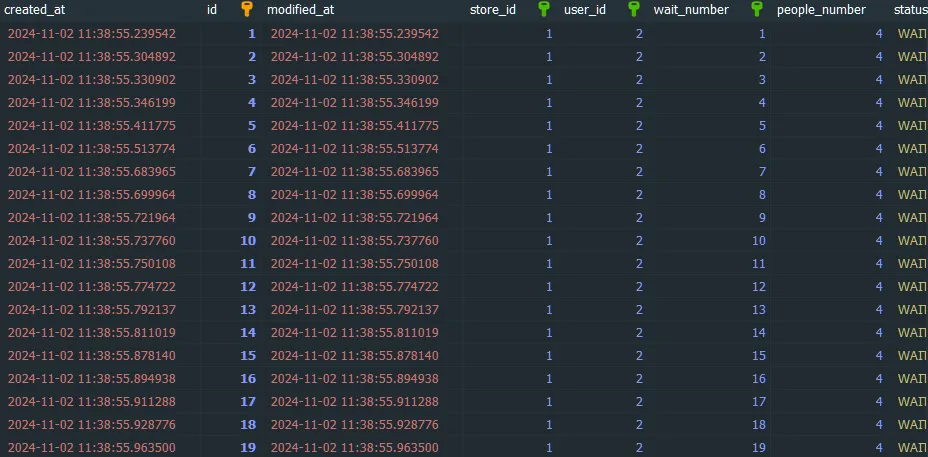
사용자 1000명이 음식점에 몰려서 한꺼번에 웨이팅을 걸어 발권번호를 받을때 번호가 중복으로 발급되는 현상 발생!!
※ 코드
@Override
@Transactional
public synchronized void waitingCreate(Long userId , Long storeId , WaitingRequest.Create create) {
User user = userRepository.findById(userId).orElseThrow(() -> new NotFoundException(ResponseCode.NOT_FOUND_USER));
Store store = storeRepository.findById(storeId).orElseThrow(() -> new NotFoundException(ResponseCode.NOT_FOUND_STORE));
LocalDate today = LocalDate.now();
long maxWaitNumber = waitingRepository.maxWaitNumber(storeId , today);
Waiting waiting = Waiting.builder()
.waitNumber(maxWaitNumber)
.waitingTime(LocalDateTime.now())
.peopleNumber(create.peopleNumber())
.status(WaitingStatus.WAITING)
.user(user)
.store(store)
.build();
waitingRepository.save(waiting);
}※ DB 스키마

※ 번호가 중복되는 것을 확인

문제의 원인
동시다발적인 요청 처리 시 DB 단위에서 동시성 제어 부재로 발생한 데이터 불일치이며 해결 방법을 모색해야 했습니다.
해결 방안
| 방법 | 정의 | 작동 방식 | 장점 | 단점 |
| Optimistic Locking (낙관적 잠금) |
데이터베이스의 자원이 동시에 여러 트랜잭션에 의해 접근될 수 있다는 가정하에 충돌이 발생하지 않을 것이라고 낙관적으로 판단하는 방식 | 각 데이터 레코드에 버전 번호를 부여하여 업데이트 시 버전 번호를 비교! 업데이트 시점에 버전이 일치하지 않으면 예외를 발생시켜 재시도 |
잠금으로 인한 성능 저하가 적고, 트랜잭션이 충돌하지 않을 경우 효율적 | 높은 충돌율이 예상될 때 성능 저하가 발생가능성 있음 |
| Pessimistic Locking (비관적 잠금) |
데이터에 대한 잠금을 사용하여 다른 트랜잭션이 해당 데이터를 읽거나 수정하지 못하도록 하는 방식 | 데이터베이스의 특정 행이나 테이블에 대해 잠금을 설정하고, 해당 자원에 대한 접근을 제어 | 데이터의 일관성을 보장하며, 동시에 발생하는 충돌을 방지 | 잠금으로 인해 성능 저하가 발생할 수 있으며, 교착 상태(Deadlock)가 발생할 위험 |
| synchronized | Java에서 스레드간의 동기화를 보장하기 위해 사용하는 키워드입니다. 특정 블록이나 메서드에 대해 한 번에 하나의 스레드만 접근 가능하도록 제한하여 공유 자원의 일관성을 유지하는 방식 | synchronized 메서드에 진입하려면 해당 객체의 뫼터 락을 흭득해야 하며 한 스레드가 락을 흭득한 상태에서는 다른 스레드는 메서드에 접근 불가 | 추가적인 라이브러리없이 synchronized 키워드 사용으로 구현이 가능하고 데이터 일관성을 보장 | 락이 설정된 영역에는 한 번에 하나의 스레드만 접근 가능하므로 병렬 처리 성능 감소 및 데드락이 발생할 위험 |
| Atomic Counter (원자적 카운터) |
데이터베이스나 인메모리 데이터베이스(예: Redis)에서 원자적으로 카운터 값을 증가시키는 방식 | Redis의 INCR 명령어 같은 원자적 연산을 사용해 카운터 값을 증가 | 높은 동시성을 지원하며, 중복 번호를 방지 | Redis 같은 외부 시스템에 의존해야 하므로, 데이터베이스와의 일관성 유지에 추가적인 고려가 필요 |
해결 과정
낙관적 락 적용 및 비관적 락 적용
※ 코드
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "waiting")
public class Waiting extends Timestamped {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private Long waitNumber;
@Column(nullable = false)
private LocalDateTime waitingTime;
@Column(nullable = false)
private Long peopleNumber;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private WaitingStatus status;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id" , nullable = false)
private User user;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "store_id" , nullable = false)
private Store store;
@Version
private Long version;
}적용 하였고 테스트를 해보았습니다.
Jmeter 테스트!

Jmeter로 수치를 기록하지 못한 이유는 DB를 보고 동시성 제어가 해결이 안되었음을 확인했기 때문입니다.
이는 왜 동시성 제어가 해결되지 않았을까 라는 의문에 빠졌고 하나의 결론에 도달하게 되었습니다.
낙관적 락을 걸었음에도 동시성 제어가 해결이 안된 이유는 낙관적 락에 대한 개념 이해가 부족한 상황에서 사용하려고 했기 때문입니다. Waiting 엔티티 생성 시점에서는 버전 정보가 없으므로 낙관적 락이 제대로 적용되지 않았습니다.
※ 즉 waitingCreate 메서드에서 Waiting 엔티티가 생성될때 버전관리가 시작되지 않아 여러 쓰레드에서 번호 채번 과정에서 발권번호가 중복처리 나는 것!!
이 또한 비관적락에서도 똑같이 적용했고 이는 현재 구성된 코드에서는 해결하지 못하는 방안이며 코드를 개선함으로써 해결할수 있음을 확인했습니다. 하지만 해당 해결 방법은 insert 문안에 select문을 넣는 방식이며 거기에 lock을 걸어서 하기에는 필요 이상의 넓은 범위를 잠글 수가 있어서 코드 변경없이 비관적 락 또한 방법이 아니라 판단했습니다.
Synchronized
※ 코드
@Transactional
public synchronized void waitingCreate(Long userId , Long storeId , WaitingRequest.Create create) {
User user = userRepository.findById(userId).orElseThrow(() -> new NotFoundException(ResponseCode.NOT_FOUND_USER));
Store store = storeRepository.findById(storeId).orElseThrow(() -> new NotFoundException(ResponseCode.NOT_FOUND_STORE));
LocalDate today = LocalDate.now();
long maxWaitNumber = waitingRepository.maxWaitNumber(today , storeId);
Waiting waiting = Waiting.builder()
.waitNumber(maxWaitNumber)
.waitingTime(LocalDateTime.now())
.peopleNumber(create.peopleNumber())
.status(WaitingStatus.WAITING)
.user(user)
.store(store)
.build();
waitingRepository.save(waiting);
}
Jmeter 테스트!


| 샘플 수 | 10,000 |
| 평균 응답 시간 | 3,551ms |
| 최소 응답 시간 | 76ms |
| 최대 응답 시간 | 5,282ms |
| 오류율 | 0% |
| 처리량 | 257.4/sec |
Synchronized 를 사용해서 발권번호가 중복되는 현상을 해결했습니다.
다만 성능적으로 많이 떨어지는 것을 확인했고 Redis로도 진행해보면서 성능 비교를 해보기로 했습니다.
원자적 카운터(Redis)
Redis를 사용하여 진행해보았으나 RedisTemplate가 아닌 RedisssonClient를 사용하여 진행했고 이렇게 결정하게 된 이유는 아래와 같습니다.
- RAtomicLong
- 원자성 보장: 원자적 카운터를 제공하여 동시에 여러 요청이 들어와도 대기 번호가 중복되지 않음
- 효율적인 대기 번호 관리 : 대기 번호를 원자적으로 증가시켜 대기열의 각 항목에 고유한 번호를 할당
- 성능 최적화 : Redis의 메모리 기반 특성을 활용해 빠른 속도로 대기 번호 생성
- RQueue
- FIFO 구조 : 웨이팅 대기열에 적합한 데이터 구조로 대기 요청을 순서대로 처리
- 동시 접근 지원 : 여러 스레드가 동시에 대기열에 접근할 수 있어, 대기 요청을 효율적으로 처리
- 간편한 데이터 관리 : 대기 요청을 쉽게 추가하고 제거할 수 있으며, 대기 항목을 직관적으로 관리
- RMap
- 단일 키-값 저장 : key-value로 저장하는 데이터 구조로 단일 값을 매핑하여 저장
- 효율적인 조회 및 업데이트 : 키를 사용하여 빠르게 조회하고 업데이트 할 수 있으며 대기 번호과 같은 고유한 식별자를 사용하여 대기 정보를 쉽게 관리할 수 있게 해주며, 특정 대기 번호에 대한 대기 정보를 신속하게 가져옴
- 데이터 일관성 유지 : 단일 값을 저장하기 때문에 데이터의 일관성을 유지하는데 유리하고 중복된 데이터를 방지
- RScoredSortedSet
- 점수 기반 정렬 : 각 요소는 점수와 함께 저장되며 점수를 기준으로 오름차순으로 자동 정렬
- 중복 방지 : 각 요소는 고유해야하며 중복된 요소를 저장하지 않음
- 효율적인 범위 조회 : 점수의 범위 또는 순위를 기준으로 데이터를 효율적으로 조회 가능
등과 같이 여러 기능들을 제공해주기에 RedissonClient로 구현하기로 했습니다.
RAtomicLong + RQueue + RMap
※ 코드
public void waitingCreate(Long userId, Long storeId, WaitingRequest.Create create) {
// 키 이름 구성: store:1:waiting
String redisKey = getRedisKey(storeId);
// RAtomicLong
RAtomicLong waitingNumber = redissonClient.getAtomicLong(redisKey + KEY_NUMBER); // 대기 번호용 AtomicLong
long maxWaitNumber = waitingNumber.incrementAndGet(); // 현재 값에 1을 더하고 반환
// RQueue
RQueue<Object> waitingQueue = redissonClient.getQueue(redisKey + KEY_QUEUE); // 대기열
// RSetMultimap
RMap<Long, Waiting> waitingMap = redissonClient.getMap(redisKey + KEY_MAP); // 대기 정보 저장용 멀티맵
// 대기 항목 생성
Waiting waiting = Waiting.builder()
.waitNumber(maxWaitNumber)
.waitingTime(LocalDateTime.now())
.peopleNumber(create.peopleNumber())
.status(WaitingStatus.WAITING)
.build();
// 대기 정보를 RSetMultimap에 추가
waitingMap.put(maxWaitNumber, waiting);
// 대기열에 대기 항목 추가
waitingQueue.add(maxWaitNumber);
}
※ Redis에 코드 작성의도대로 들어갔는지 확인!

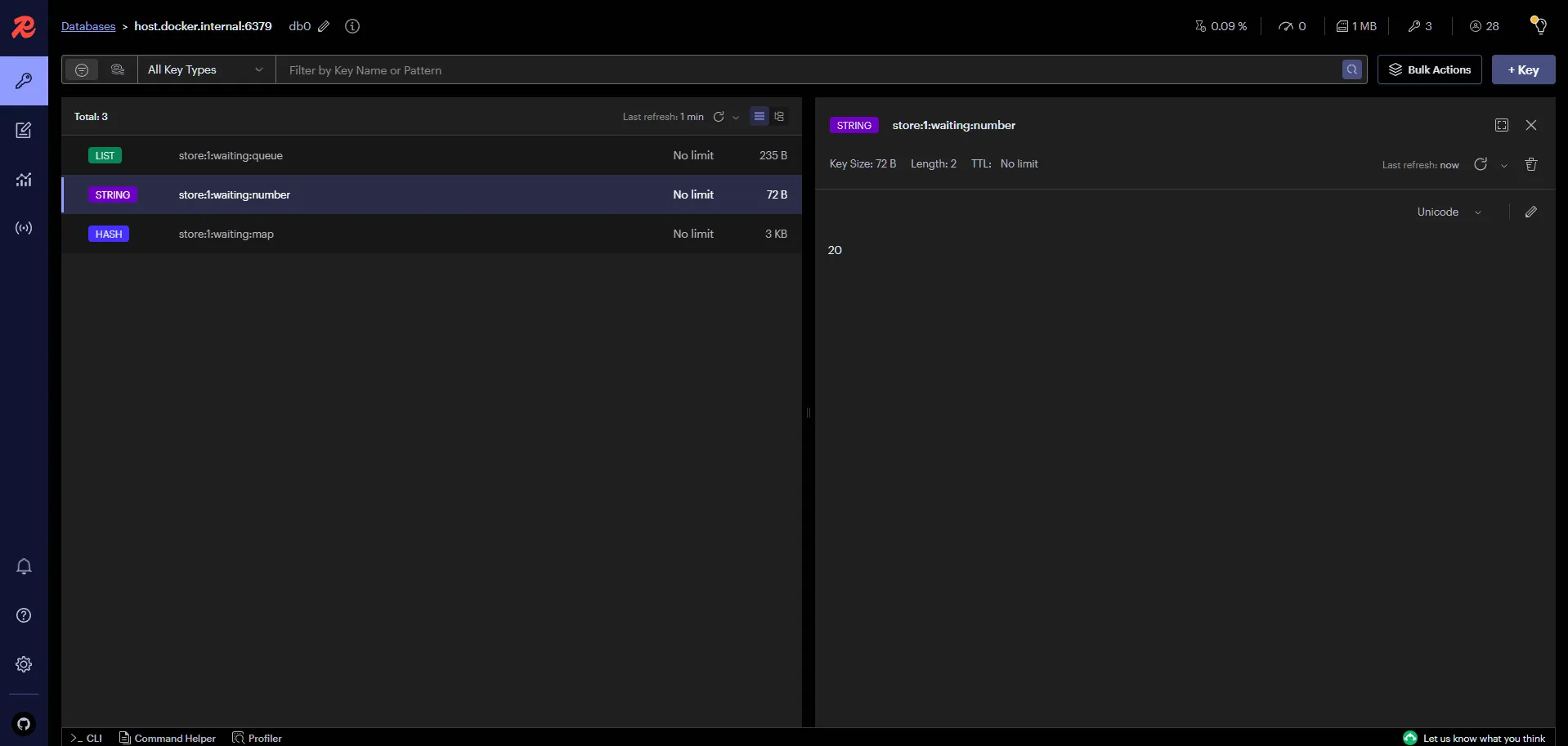
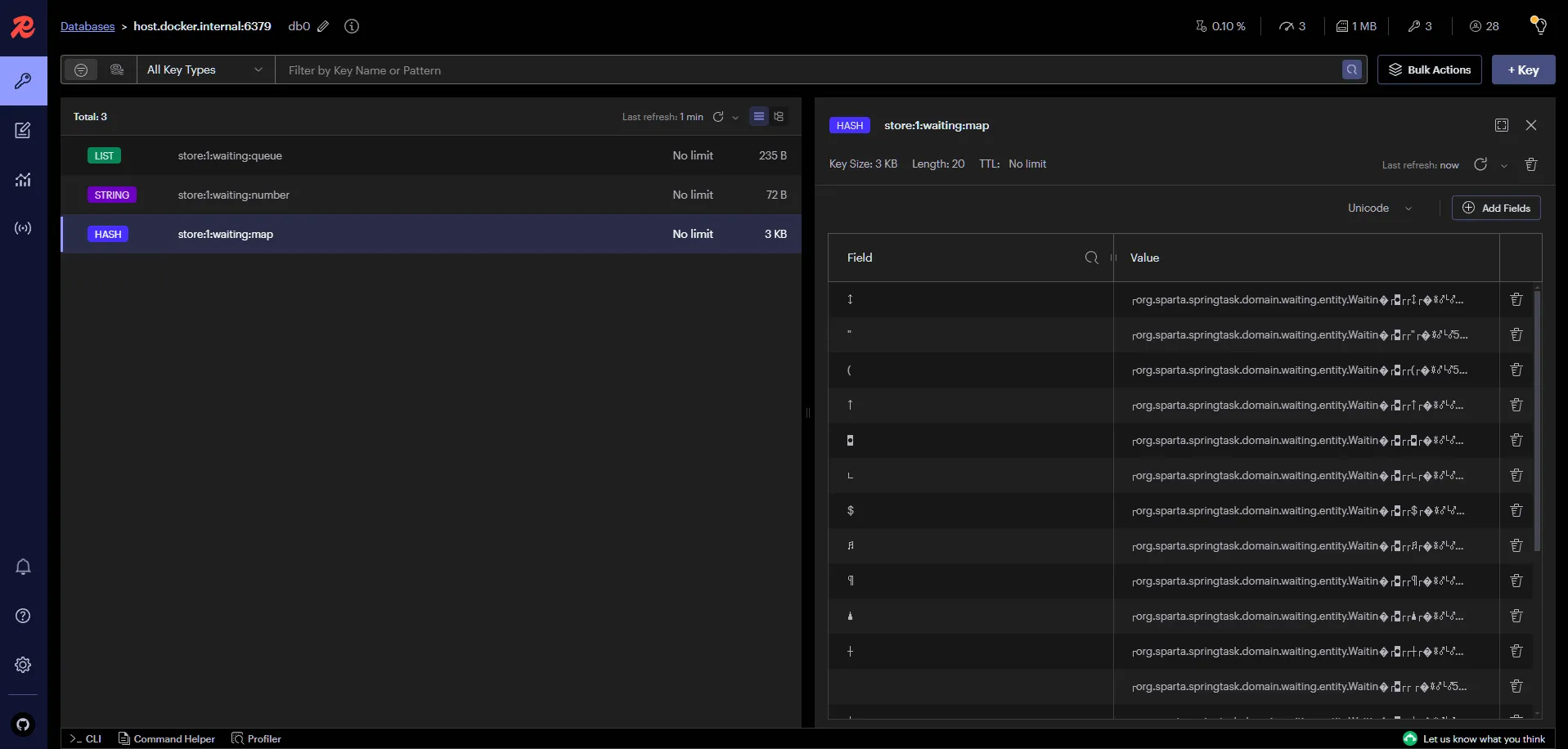
※ 순서대로 발권번호가 채번되었는지 확인 겸 웨이팅 대기열 1순위 처리
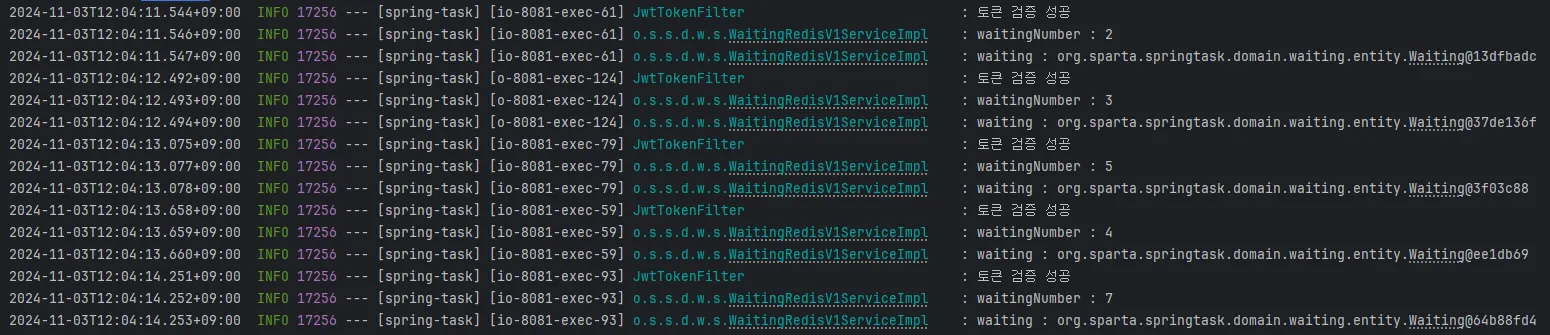
웨이팅 번호가 뒤죽박죽으로 Queue에 들어가는 것을 확인했습니다!!!
Jmeter 테스트!

| 샘플 수 | 10,000 |
| 평균 응답 시간 | 294ms |
| 최소 응답 시간 | 3ms |
| 최대 응답 시간 | 807ms |
| 오류율 | 0% |
| 처리량 | 2,070.4/sec |
※ Redis 확인


성능이 압도적으로 빨라진 것을 확인할 수 있었습니다.
다만 웨이팅 번호가 순서대로 들어가지 않은 문제가 발생하였고 RedissonLock를 활용해서 테스트해보기로 했습니다.
RAtomicLong + RQueue + RMap + RedissonLock
※ 코드
RedissonLockAspect 코드
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class RedissonLockAspect {
private final RedissonClient redissonClient;
@Around("@annotation(org.sparta.springtask.common.annotation.RedissonLock)")
public Object redissonLock(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
RedissonLock annotation = method.getAnnotation(RedissonLock.class);
String lockKey = "";
char c = annotation.value().charAt(0);
if (c == '#') { // 파라미터 기반
String parameterName = annotation.value().substring(1);
Object[] args = joinPoint.getArgs();
String value = null;
for (int i = 0; i < signature.getParameterNames().length; i++) {
if (signature.getParameterNames()[i].equals(parameterName)) {
value = args[i] == null ? "" : args[i].toString();
break;
}
}
if (value == null) {
throw new ApiException(HttpStatus.BAD_REQUEST , ResponseCode.REDISSON_ANNOTATION_ERROR.getMessage());
}
lockKey = annotation.value() + ":" + value;
} else if (c == '@') { // 메서드명 기반
lockKey = annotation.value();
} else {
throw new ApiException(HttpStatus.BAD_REQUEST , ResponseCode.REDISSON_ANNOTATION_ERROR.getMessage());
}
log.debug("redissonLock lockKey:{}", lockKey);
RLock lock = redissonClient.getFairLock(lockKey);
Object result = null; // 리턴 값 저장할 변수
try {
boolean lockable = lock.tryLock(annotation.waitTime(), annotation.leaseTime(), TimeUnit.MILLISECONDS);
if (!lockable) {
log.debug("Lock 획득 실패={}", lockKey);
return null;
}
log.debug("로직 수행");
result = joinPoint.proceed();
} catch (InterruptedException e) {
log.debug("에러 발생");
throw e;
} finally {
log.debug("락 해제");
lock.unlock();
}
return result;
}
}
Annotation > RedissonLock 코드
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface RedissonLock {
String value(); // Lock의 이름 (고유값)
long waitTime() default 5000L; // Lock획득을 시도하는 최대 시간 (ms)
long leaseTime() default 2000L; // 락을 획득한 후, 점유하는 최대 시간 (ms)
}
WatingService 코드
@Override
@RedissonLock("#storeId")
public void waitingCreate(Long userId, Long storeId, WaitingRequest.Create create) {
// 키 이름 구성: store:1:waiting
String redisKey = getRedisKey(storeId);
// RAtomicLong
RAtomicLong waitingNumber = redissonClient.getAtomicLong(redisKey + KEY_NUMBER); // 대기 번호용 AtomicLong
long maxWaitNumber = waitingNumber.incrementAndGet(); // 현재 값에 1을 더하고 반환
// RQueue
RQueue<Object> waitingQueue = redissonClient.getQueue(redisKey + KEY_QUEUE); // 대기열
// RSetMultimap
RMap<Long, Waiting> waitingMap = redissonClient.getMap(redisKey + KEY_MAP); // 대기 정보 저장용 멀티맵
// 대기 항목 생성
Waiting waiting = Waiting.builder()
.waitNumber(maxWaitNumber)
.waitingTime(LocalDateTime.now())
.peopleNumber(create.peopleNumber())
.status(WaitingStatus.WAITING)
.build();
// 대기 정보를 RSetMultimap에 추가
waitingMap.put(maxWaitNumber, waiting);
// 대기열에 대기 항목 추가
waitingQueue.add(maxWaitNumber);
}
음식점ID 기반으로 Lock이 걸려서 차례대로 값이 들어가야해서 저렇게 처리해두었습니다.
Jmeter 테스트

| 샘플 수 | 10,000 |
| 평균 응답 시간 | 2,930ms |
| 최소 응답 시간 | 5ms |
| 최대 응답 시간 | 11,555ms |
| 오류울 | 0.03% |
| 처리량 | 264.3/sec |
※ Redis에 코드 작성의도대로 들어갔는지 확인!
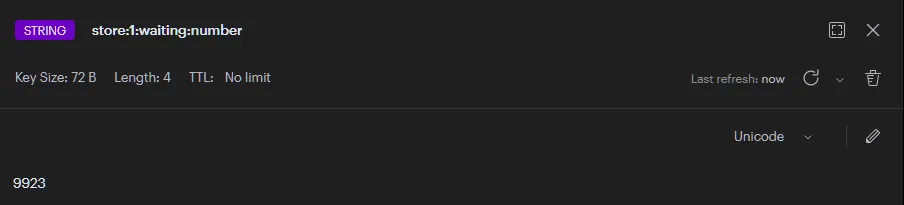
77개의 일부 데이터가 들어가지 못하는 점을 확인 했습니다.
※ 에러 발생

java.lang.IllegalMonitorStateException: attempt to unlock lock, not locked by current thread by node id: c858838c-e446-4e60-958a-85ece91ac3b6 thread-id: 235
IllegalMonitorStateException 오류는 락을 잘못 관리할 때 발생한다고 합니다. 이를 통해 락 관리를 잘못하고 있다는 것을 확인했고 락을 획득한 스레드만이 해제할 수 있도록 코드를 수정하고, 락 획득 여부를 확인한 후에 unlock()을 호출하도록 변경하여 재 시도를 해보겠습니다.
※ 다만 Redis에 값이 제대로 들어가고 있는 것은 확인 되었습니다.
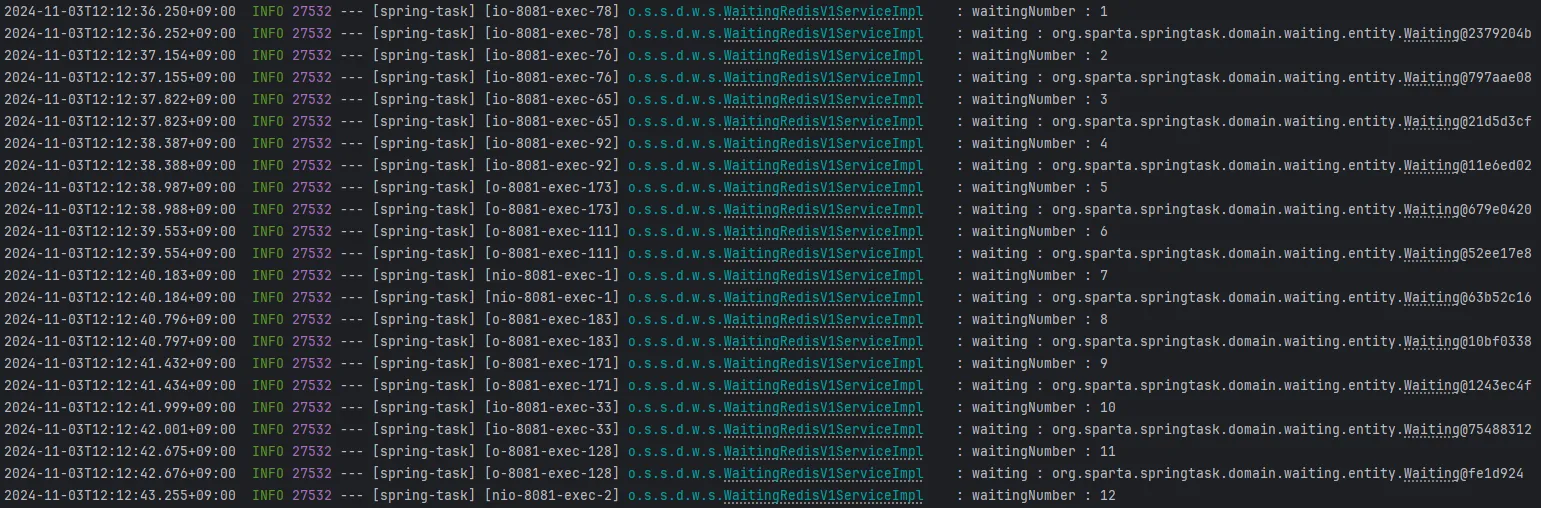
RAtomicLong + RQueue + RMap + RedissonLock(리뉴얼)
※ 코드
@Around("@annotation(org.sparta.springtask.common.annotation.RedissonLock)")
public Object redissonLock(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
RedissonLock annotation = method.getAnnotation(RedissonLock.class);
String lockKey = "";
char c = annotation.value().charAt(0);
if (c == '#') { // 파라미터 기반
String parameterName = annotation.value().substring(1);
Object[] args = joinPoint.getArgs();
String value = null;
for (int i = 0; i < signature.getParameterNames().length; i++) {
if (signature.getParameterNames()[i].equals(parameterName)) {
value = args[i] == null ? "" : args[i].toString();
break;
}
}
if (value == null) {
throw new ApiException(HttpStatus.BAD_REQUEST , ResponseCode.REDISSON_ANNOTATION_ERROR.getMessage());
}
lockKey = annotation.value() + ":" + value;
} else if (c == '@') { // 메서드명 기반
lockKey = annotation.value();
} else {
throw new ApiException(HttpStatus.BAD_REQUEST , ResponseCode.REDISSON_ANNOTATION_ERROR.getMessage());
}
log.debug("redissonLock lockKey:{}", lockKey);
RLock lock = redissonClient.getFairLock(lockKey);
// 수정 부분!!
boolean lockable = lock.tryLock(annotation.waitTime(), annotation.leaseTime(), TimeUnit.MILLISECONDS);
if (!lockable) {
log.debug("Lock 획득 실패={}", lockKey);
return null;
}
Object result = null; // 리턴 값 저장할 변수
try {
log.debug("로직 수행");
result = joinPoint.proceed();
} catch (InterruptedException e) {
log.debug("에러 발생");
throw e;
} finally {
// 수정 부분 : 현재 스레드가 락을 보유하고 있는지 확인
if (lock.isHeldByCurrentThread()) {
log.debug("락 해제");
lock.unlock();
}
}
return result;
}
Jmeter 테스트!

| 샘플 수 | 10,000 |
| 평균 응답 시간 | 2,552ms |
| 최소 응답 시간 | 5ms |
| 최대 응답 시간 | 7,069ms |
| 오류율 | 0.00% |
| 처리량 | 360.0/sec |
※ Redis 결과
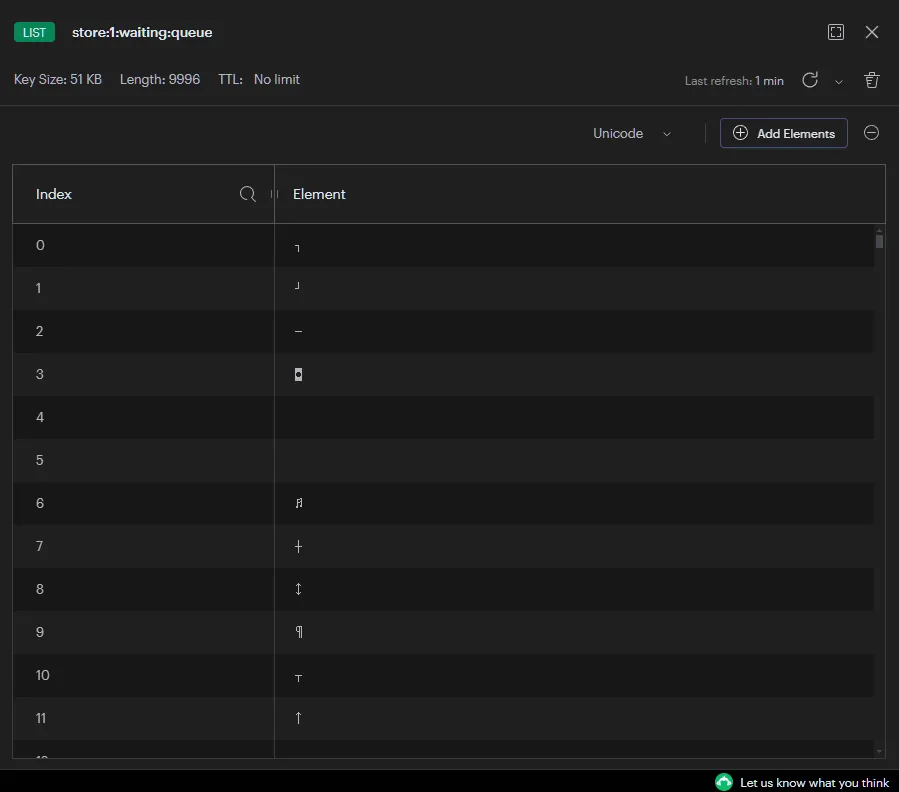

※ 웨이팅 1순위 처리 결과

RAtomicLong + RScoredSortedSet
※ 코드
@Override
public void waitingCreate(Long userId, Long storeId, WaitingRequest.Create create) {
// 키 이름 구성: store:1:waiting
String redisKey = getRedisKey(storeId);
// RAtomicLong
RAtomicLong waitingNumber = redissonClient.getAtomicLong(redisKey + KEY_NUMBER); // 대기 번호용 AtomicLong
long maxWaitNumber = waitingNumber.incrementAndGet(); // 현재 값에 1을 더하고 반환
RScoredSortedSet<Waiting> sortedSet = redissonClient.getScoredSortedSet(redisKey + KEY_SCORE);
// 대기 항목 생성
Waiting waiting = Waiting.builder()
.waitNumber(maxWaitNumber)
.waitingTime(LocalDateTime.now())
.peopleNumber(create.peopleNumber())
.status(WaitingStatus.WAITING)
.build();
sortedSet.add((double) maxWaitNumber, waiting);
}
Jmeter 테스트!

| 샘플 수 | 10,000 |
| 평균 응답 시간 | 357ms |
| 최소 응답 시간 | 2ms |
| 최대 응답 시간 | 1,882ms |
| 오류율 | 0.00% |
| 처리량 | 2,282.6/sec |
※ Redis 결과


※ 웨이팅 1순위 처리 결과

RAtomicLong + RScoredSortedSet + RedissonLock(리뉴얼)
Jmeter 테스트!

| 샘플 수 | 10,000 |
| 평균 응답 시간 | 2,288ms |
| 최소 응답 시간 | 5ms |
| 최대 응답 시간 | 6,909ms |
| 오류율 | 0.00% |
| 처리량 | 360.1/sec |
※ Redis 확인

한눈에 보기

흐름도

번외(Select 부분)
10000건 기준으로 조회를 해보았습니다.
DB 조회 하는 방식!
※ 코드
@Override
public Page<WaitingResponse.List> getWaitingList(Long userId , Long storeId , WaitingRequest.List list) {
Pageable pageable = PageRequest.of(list.page() - 1, list.size());
LocalDate today = LocalDate.now();
Page<Waiting> waiting = waitingRepository.findWaitingByList(userId , storeId , WaitingStatus.WAITING , today , pageable);
return waiting.map(it -> new WaitingResponse.List(it.getWaitNumber() , it.getPeopleNumber()));
}
redis로 조회 (RQueue + RMap + RAtomicLong)
※ 코드
@Override
public Page<WaitingResponse.List> getWaitingList(Long userId, Long storeId, WaitingRequest.List list) {
// 키 이름 구성
String redisKey = getRedisKey(storeId);
// 대기열에서 대기 항목 가져오기
RQueue<Object> waitingQueue = redissonClient.getQueue(redisKey + KEY_QUEUE);
RMap<Long, Waiting> waitingMap = redissonClient.getMap(redisKey + KEY_MAP);
// 대기 항목을 페이지 형식으로 변환
int pageNumber = list.page() - 1; // 페이지 번호
int pageSize = list.size(); // 페이지 크기
List<Object> waitNumbers = waitingQueue.stream()
.skip((long) pageNumber * pageSize)
.limit(pageSize)
.toList();
// Set으로 변환하여 getAll 사용
Set<Long> waitNumberSet = new HashSet<>();
for (Object waitNumber : waitNumbers) {
waitNumberSet.add((Long) waitNumber);
}
// 대기 정보를 한 번에 가져오기
Map<Long, Waiting> waitingData = waitingMap.getAll(waitNumberSet);
// 대기 응답 리스트 생성
List<WaitingResponse.List> waitingResponses = waitingData.values().stream()
.map(waiting -> new WaitingResponse.List(waiting.getWaitNumber(), waiting.getPeopleNumber()))
.collect(Collectors.toList());
return new PageImpl<>(waitingResponses, PageRequest.of(pageNumber, pageSize), waitingQueue.size());
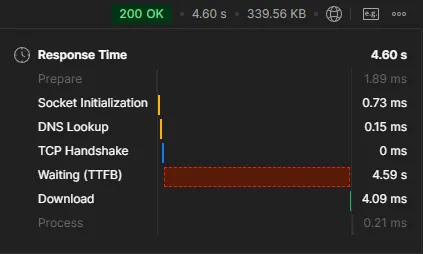
}
redis로 조회 (RScoredSortedSet + RAtomicLong)
※ 코드
@Override
public Page<WaitingResponse.List> getWaitingList(Long userId, Long storeId, WaitingRequest.List list) {
// 키 이름 구성
String redisKey = getRedisKey(storeId);
// 대기 항목을 스코어드 정렬 세트에서 가져오기
RScoredSortedSet<Waiting> sortedSet = redissonClient.getScoredSortedSet(redisKey + KEY_SCORE);
// 페이지 정보를 기반으로 대기 항목 가져오기
int pageNumber = list.page() - 1; // 페이지 번호 (0-based)
int pageSize = list.size(); // 페이지 크기
// 스코어드 정렬 세트에서 대기 항목을 페이지 형식으로 변환
List<WaitingResponse.List> waitingResponses = sortedSet.valueRange(pageNumber * pageSize, (pageNumber + 1) * pageSize).stream()
.map(waiting -> new WaitingResponse.List(waiting.getWaitNumber(), waiting.getPeopleNumber()))
.collect(Collectors.toList());
return new PageImpl<>(waitingResponses, PageRequest.of(pageNumber, pageSize), sortedSet.size());
}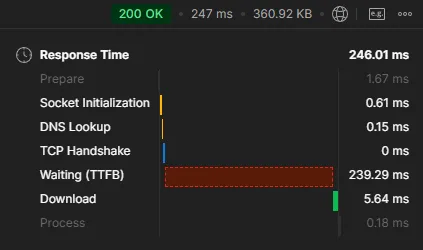
※ Redis vs Database
기본적으로 조회시 Redis가 빠르다는 것은 알고 있는 사실입니다.
다만 조회시 의외인 점을 발견했습니다. 많은 량의 데이터 조회시 Redis가 느린 경우도 존재한다는 점입니다.
Redis가 느려지는 이유는 대략적으로 몇가지가 있다는 점을 확인했습니다.
- 데이터 조회 방식 문제
- Redis에서 데이터를 조회할 때 LRANGE나 HGETALL과 같이 범위 조회를 할 경우 전체 데이터를 메모리에 로드하고 범위를 제한하는 방식이기 때문에 범위 조회나 필터링이 최적화 되어 있는 데이터베이스보다 느려질 수 있습니다.
- 데이터베이스는 인덱스를 이용하여 조회 범위를 효율적으로 줄이는 반면, Redis는 단순히 모든 데이터를 다룬 후 클라이언트에서 필요한 데이터를 선택하는 방식입니다. 이런 차이 떄문에 조회 성능이 느려질 수 있습니다.
- 메모리 압력 및 GC 영향
- Redis의 메모리 사용량이 높아지면 Garbage Collection(GC)가 자주 발생해 응답 시간이 지연될 수 있습니다. Redis는 기본적으로 메모리 기반으로 동작하기 때문에 메모리 압력이 증가할 경우 GC로 인해 처리 속도가 느려질 수 있습니다.
- 데이터베이스는 디스크를 활용하기 때문에 메모리 압력으로 인한 성능 저하가 Redis보다 덜합니다.
- 네트워크 통신 오버헤드
- Redis는 기본적으로 네트워크를 통한 통신을 하므로, 네트워크 환경이 불안정하거나 대량의 데이터를 반환할 경우 응답 시간이 느려질 수 있습니다.
- 데이터베이스의 경우 애플리케이션이 같은 서버에 있거나 최적화된 네트워크 환경에서 동작할 경우 Redis보다 응답 속도가 빠를 수 있습니다
- Redis의 단일 스레드 구조
- Redis는 단일 스레드로 동작하기 때문에 많은 양의 데이터를 한 번에 다룰 때 처리 시간이 길어질 수 있습니다. 특히, 동시에 여러 클라이언트가 큰 데이터를 요청하면 Redis가 모든 요청을 순차적으로 처리하게 되어 응답 속도가 느려질 수 있습니다.
- 데이터베이스는 멀티 스레드 구조로 병렬 처리가 가능해, 동일한 상황에서 더 빠르게 응답할 수 있습니다.
- 데이터 구조의 비효율적 사용
- Redis에서 데이터 조회 시, HSET, ZADD 등의 데이터 구조를 올바르게 사용하지 않으면 조회 성능이 저하될 수 있습니다. 예를 들어, 키-값 구조에 적합하지 않은 데이터에 LIST나 SET을 사용하면 성능이 떨어질 수 있습니다.
- 데이터베이스는 관계형 데이터에 최적화되어 있으며, 대량 데이터 조회 시 인덱스 등의 최적화를 통해 빠르게 데이터를 조회할 수 있습니다.
- 대량 데이터 조회 시 캐싱의 한계
- Redis는 보통 빠른 조회를 위한 캐시 역할로 많이 사용됩니다. 하지만 캐시는 자주 변경되는 데이터에 적합하지 않으며, 일정 용량 이상의 대량 데이터를 자주 조회할 경우 캐싱의 효과가 떨어질 수 있습니다.
- 데이터베이스는 대량 데이터에 대해 최적화된 처리 메커니즘을 가지고 있어 대량 조회 시 Redis보다 유리한 경우가 많습니다.
해결 완료
최종적으로는 RAtomicLong + RScoredSortedSet + RedissonLock(리뉴얼) 를 선택해 구현완료 했으며 해결하면서 느낀점은 아래와 같습니다.
- 10,000건 기준이긴 하나 create 하는 과정은 DB보다 빨랐고 select 하는 과정에서는 DB랑 비슷한 성능을 보였으나 RAtomicLong + RQueue + RMap + RedissonLock(리뉴얼)에 비해서 속도가 빠른 점을 확인했기에 선택
- 데이터 크기는 RAtomicLong + RQueue + RMap + RedissonLock(리뉴얼) 에 비해 2배 가량 차지하는 것을 파악함. 비용이 많이 없다면 주기적으로 DB에 데이터를 이관하는 작업으로 하여 대량 데이터의 경우는 DB를 통해 조회하는 방향으로 틀어야 함
- 이번 과정을 걸치면서 설계를 제대로 잡고 들어가야 한다는 점을 명확하게 배웠습니다.
결론
- Redis는 무조건 빠르지 않다는 점!
- Redis는 높은 동시성 상황에서는 유리하지만 대규모 조회 상황에서는 오히러 RDBMS가 더 나을 수 있는 점
- Redis를 사용할 때는 데이터 크기 , 요청 패턴을 고려
- 결론 및 교훈
- Redis 도입으로 문제를 해결했지만 기술 선택은 상황과 요구상황에 따라 달라져야 함
- 기술 도입 시 실제 환경에서의 성능 테스트가 반드시 필요하다는 점!
'코딩 공부 > Spring' 카테고리의 다른 글
| [Spring] RedisTemplate vs Redisson (0) | 2024.11.22 |
|---|---|
| [Spring] Spring Batch란? feat.DB 분리 작업 (0) | 2024.11.10 |
| [Spring] 소나클라우드(SonaCloud)란? (0) | 2024.10.22 |
| [Spring] Redis Cluster localhost에 구현하여 적용 (0) | 2024.10.15 |
| [Spring] Redis 동시성 문제 Redisson으로 해결! (0) | 2024.10.08 |


